프롬프트를 잘 쓰면 충분하던 시기가 있었습니다. 2024년까지는 그랬습니다. AI 에이전트가 코드를 작성하고, 문서를 생성하고, 워크플로우를 실행하는 단계로 넘어오면서 상황이 달라졌습니다. 프롬프트 하나로 통제할 수 있는 범위를 넘어선 것입니다.
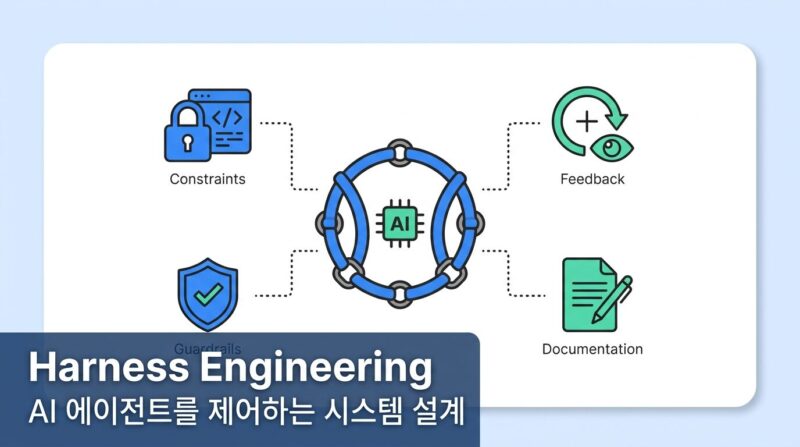
하네스 엔지니어링(Harness Engineering)은 이 문제에 이름을 붙인 개념입니다. 에이전트가 실수할 때마다, 그 실수를 반복하지 못하도록 시스템 수준에서 해결책을 설계하는 것. 이 글에서는 하네스 엔지니어링의 기원, 프롬프트에서 하네스까지의 진화 구조, 4가지 핵심 기둥을 정리합니다.
Contents
기원과 핵심 비유
2026년 2월, 하시코프(HashiCorp) 공동 창업자이자 테라폼(Terraform) 개발자인 미첼 하시모토(Mitchell Hashimoto)가 블로그에서 이 개념을 명명했습니다. 에이전트가 실수하면 같은 실수를 구조적으로 차단하는 것. 그것이 하네스 엔지니어링입니다.
며칠 뒤 OpenAI가 코덱스(Codex) 에이전트로 수동 코드 작성 없이 100만 줄 규모의 코드베이스를 구축한 사례를 공개했습니다. 에이전트가 대규모 작업을 수행하는 현실이 증명되면서, 이 개념이 업계 전반으로 확산되었습니다.
하네스(Harness)의 원래 뜻은 말에 채우는 마구입니다. 고삐, 안장, 재갈. 비유는 명확합니다. LLM 에이전트는 힘은 있지만 예측이 어렵습니다. 밭을 갈 수 있는 능력은 갖추고 있으나, 마구 없이 놓아두면 옆 밭으로 이탈합니다. 도구, 메모리, 상태 관리, 가드레일(Guardrail), 오케스트레이션(Orchestration) 없이는 안정적으로 작동하지 않습니다. 이 마구를 설계하는 것이 하네스 엔지니어링입니다.
3단계 진화 — 프롬프트에서 하네스까지
AI와 사람의 상호작용 방식은 세 단계로 진화했습니다.
프롬프트 엔지니어링(Prompt Engineering, 2022~2024). 모델에게 지시를 정확히 전달하는 데 집중한 단계입니다. 질문 구성 방식에 따라 답변 품질이 달라지던 시기입니다. 역할 부여, 단계별 사고 유도, 예시 제시 같은 기법이 이때 정립되었습니다. 단일 작업 중심이었습니다.
컨텍스트 엔지니어링(Context Engineering, 2025). 모델이 추론 시점에 참조하는 전체 맥락을 시스템 수준에서 설계하는 단계입니다. 문서, 대화 이력, 도구 정의, RAG(검색 증강 생성) 결과 등 모델이 볼 수 있는 정보의 범위와 구조를 다룹니다. 프롬프트 하나가 아니라, 프롬프트가 작동하는 환경 전체를 설계하기 시작한 것입니다.
하네스 엔지니어링(Harness Engineering, 2026). 질문이 바뀝니다. “모델이 무엇을 봐야 하는가”에서 “시스템이 무엇을 차단하고, 측정하고, 수리해야 하는가”로. 에이전트가 자율적으로 작업을 수행하는 환경에서, 실수를 사전에 방지하고 사후에 감지하는 구조를 설계하는 단계입니다.
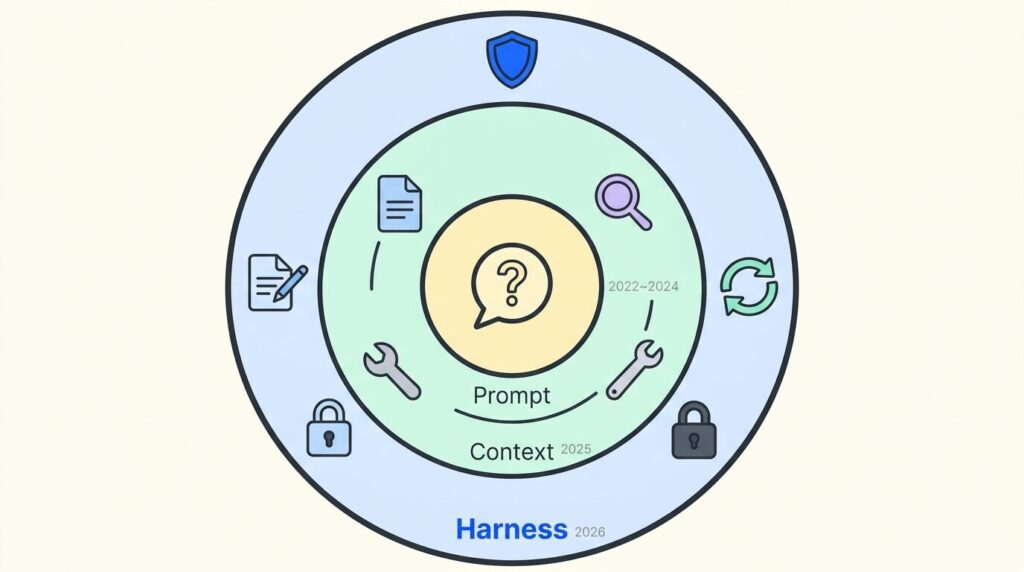
세 개념은 포함 관계입니다. 하네스가 컨텍스트를 포함하고, 컨텍스트가 프롬프트를 포함합니다(Harness ⊇ Context ⊇ Prompt). 앞 단계가 사라지는 것이 아니라, 더 넓은 구조 안에 흡수되는 것입니다.
4가지 핵심 기둥
OpenAI, 하시모토, 마틴 파울러(Martin Fowler) 사이트의 비르기타 뵈클러(Birgitta Böckeler) 분석을 종합하면, 하네스는 4가지 기둥으로 구성됩니다.
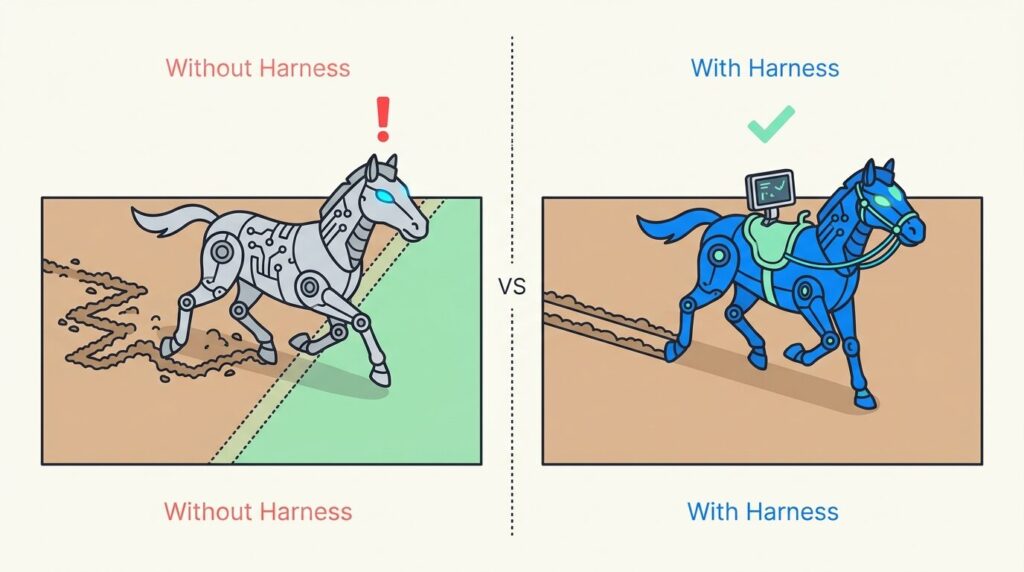
기둥 1. 아키텍처 제약(Architectural Constraints)
모듈 경계, 데이터 구조, 도메인 규칙을 기계가 읽을 수 있는 형태로 강제합니다. ADR(Architecture Decision Record), 스키마 검증기(Schema Validator) 같은 도구가 이 역할을 담당합니다. 규칙을 문서에만 적어두면 에이전트는 무시합니다. 코드로 강제해야 작동합니다.
제약이 엄격할수록 에이전트의 출력은 안정적입니다. 자유도를 줄여야 품질이 올라가는 구조입니다.
기둥 2. 피드백 루프와 관찰 가능성(Feedback Loops & Observability)
클로드 코드(Claude Code) 개발자 보리스 체르니(Boris Cherny)에 따르면, 모델에게 자기 작업을 검증할 수단을 부여하면 품질이 2~3배 향상됩니다. 에이전트가 결과를 내놓은 뒤, 그 결과를 스스로 점검하는 구조를 만드는 것입니다.
랭체인(LangChain)은 모델 변경 없이 하네스 최적화만으로 정확도를 52.8%에서 66.5%로 올렸습니다. 모델을 교체하지 않아도 제어 구조 개선만으로 성능이 달라진다는 사례입니다.
기둥 3. 검증과 가드레일(Verification & Guardrails)
앤트로픽(Anthropic) 연구에 따르면, 모델은 자기 작업을 안정적으로 평가하지 못합니다. 글을 쓴 AI가 자기 글을 점검하면 오류를 놓칩니다.
해결 구조는 생성기(Generator)와 평가기(Evaluator)의 분리입니다. 글을 쓰는 모델과 글을 점검하는 모델을 나눕니다. 여기에 결정론적 도구(린터, 타입 체커, 단위 테스트)와 AI 기반 검증(에이전트가 다른 에이전트의 코드를 리뷰)을 결합합니다.
기둥 4. 지속적 문서화(Living Documentation)
하시모토는 자신의 고스티(Ghostty) 프로젝트에서 AGENTS.md 파일을 유지합니다. 이 파일의 각 줄은 과거 에이전트가 범한 실수를 방지하는 규칙입니다. 실패할 때마다 규칙이 한 줄 추가됩니다.
OpenAI 팀은 단일 거대 지시 파일 대신, 작은 AGENTS.md가 설계 문서, 아키텍처 맵, 품질 등급 같은 더 깊은 출처를 가리키는 구조를 만들었습니다. 문서가 고정된 매뉴얼이 아니라 실패 경험이 축적되는 규칙 파일이 되는 것입니다.
엔지니어의 역할이 바뀌었다
하네스 엔지니어링의 핵심 원칙은 역할의 이동입니다. 인간은 환경을 설계하고, 의도를 명세하고, 피드백 루프를 구축합니다. 에이전트는 그 안에서 코드를 작성합니다. 엔지니어의 작업이 구현에서 시스템 설계로 옮겨간 것입니다.
무언가 실패했을 때 답은 “더 노력하라”가 아닙니다. “어떤 역량이 빠져 있고, 그것을 에이전트가 읽고 강제할 수 있게 만들려면 어떻게 해야 하는가”입니다. 실패 원인을 사람의 노력이 아니라 시스템의 부재에서 찾는 관점입니다.
이 구조는 코드에만 적용되지 않습니다. 글쓰기에서도 동일한 원리가 작동합니다. 생성기와 평가기 분리, 분량 가드레일, 원문 보존 레벨 같은 설계는 4가지 기둥 중 “검증과 가드레일”과 “아키텍처 제약”에 해당하는 글쓰기 버전의 하네스입니다.